
The AI Invoice Has Entered the Chat
Token-Maxxing is Dying, but AI-Accelerated Velocity is Not

In 2023, Red Lobster made Endless Shrimp a permanent menu item. This was fantastic news for customers who interpreted the phrase “endless shrimp” as a theological claim in need of empirical testing. It was less good news for the servers who hated refilling shrimp plates while maintaining the cheerfulness expected in American casual dining. Besides the employee attrition, it was a massive money loser, and we only know about its $11 million dollar loss because it became a part of the company’s bankruptcy story.

Red Lobster provides us with a plausible theory of the next phase of AI economics:
unlimited consumption is a sound strategy right up until the moment finance double checks the unit economics.
This is not an article about shrimp. Mostly.
For a while, AI has been living through its Endless Shrimp phase. MORE context. MORE tool use. MORE agents. MORE evals. MORE “let’s just use the best model because the stakes are high” (where “the stakes” means a Slack summary that three people will skim during lunch). Always MOOOOORE!!

Consider the AI model releases as four distinct waves:
The first wave of serious frontier models showed what might be possible, but the pricing and limited intelligence were painful enough that ambitious prototypes remained prototypes.
The second wave of models (GPT-4, Claude 3 Opus, o1, and especially GPT-4.5) were impressive, expensive, and frequently worth testing because the capabilities were moving faster and total costs still flew under the budget radar.
The third wave of models produced higher levels of intelligence at a 90% discount or more. This was the moment when the collective freaked out with better models at lower costs. Everyone freaked out, and the narrative became “intelligence would keep getting cheaper until it became too cheap to meter.”
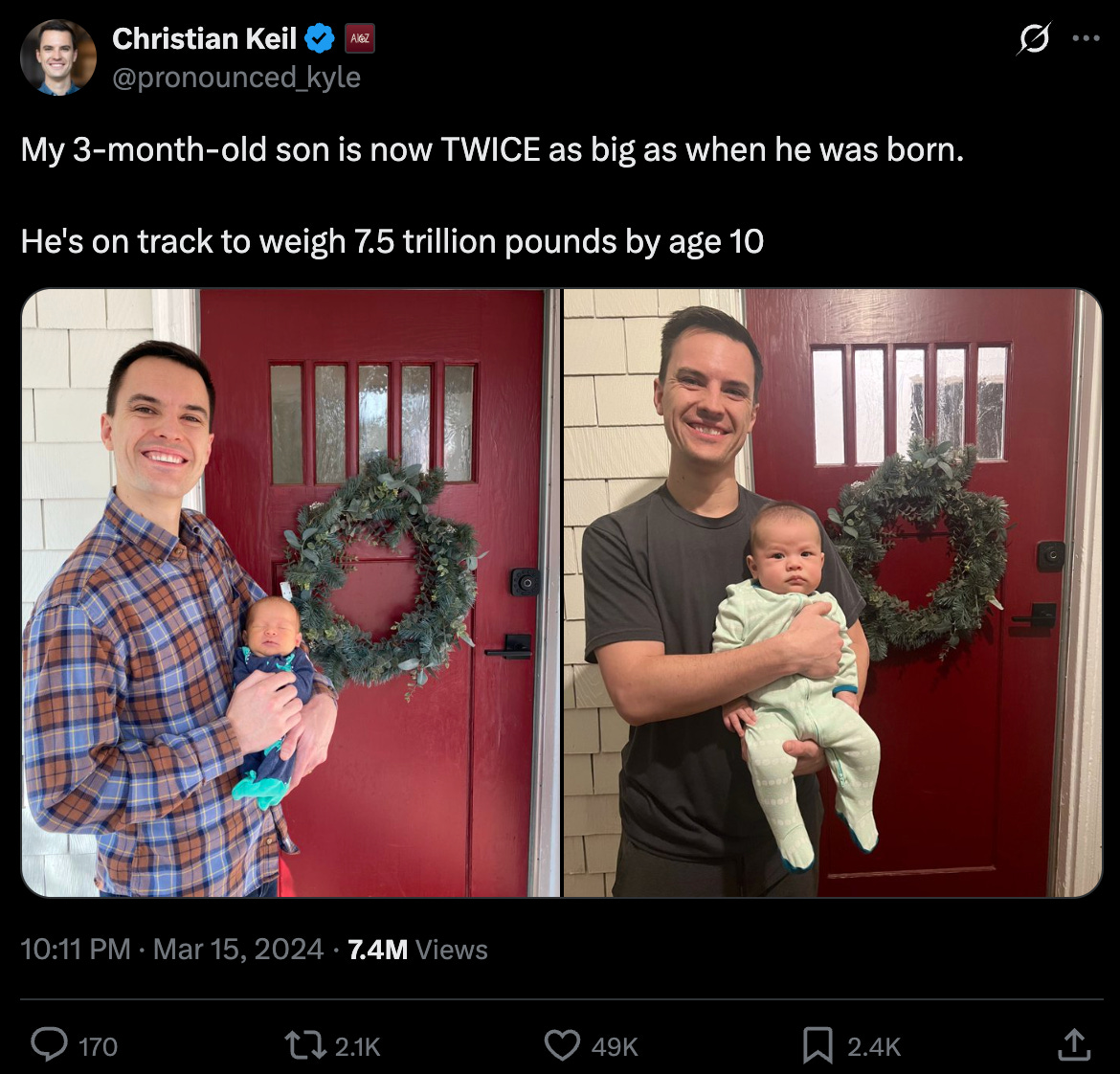
The fourth and current wave of models are steadily more intelligent, but at an increasing price. Additionally, those third wave models are being deprecated, effectively increasing the price, even as adoption and token usage is rising. Quantity is rising rapidly at the same moment price is increasing.
However, the third wave narrative was slow to die. Finance departments across the world are slowly waking up to the fourth wave of increasingly expensive models at higher consumption.
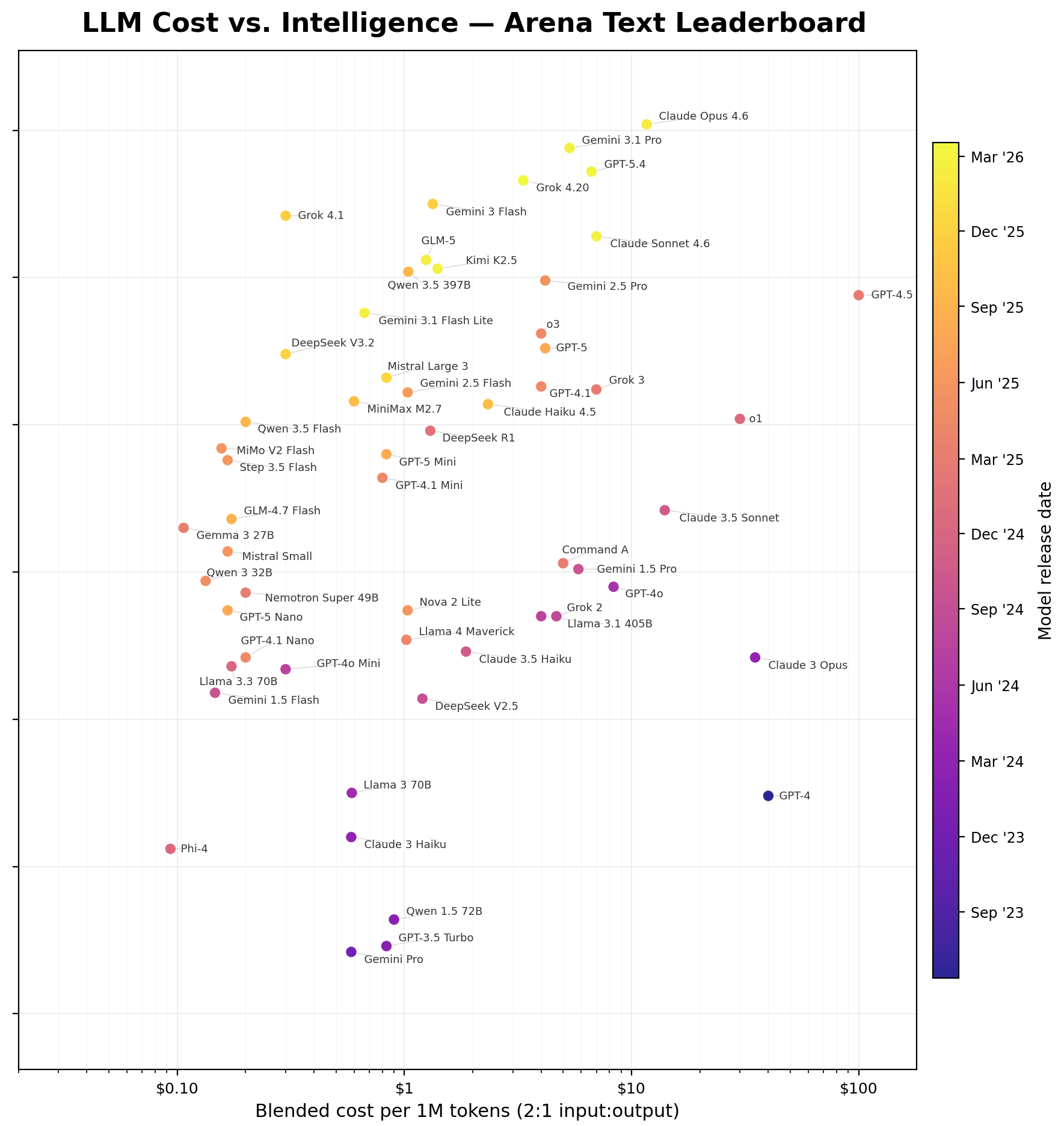
The above chart is a little busy, but it’s useful because it shows each of the waves. The latest models have been trending more expensive at the frontier. The new Mythos model simply extends the extrapolation above. Smarter and more expensive.
If you want to simply take two points in time, here’s another way of visualizing the jump from the second to the fourth wave:
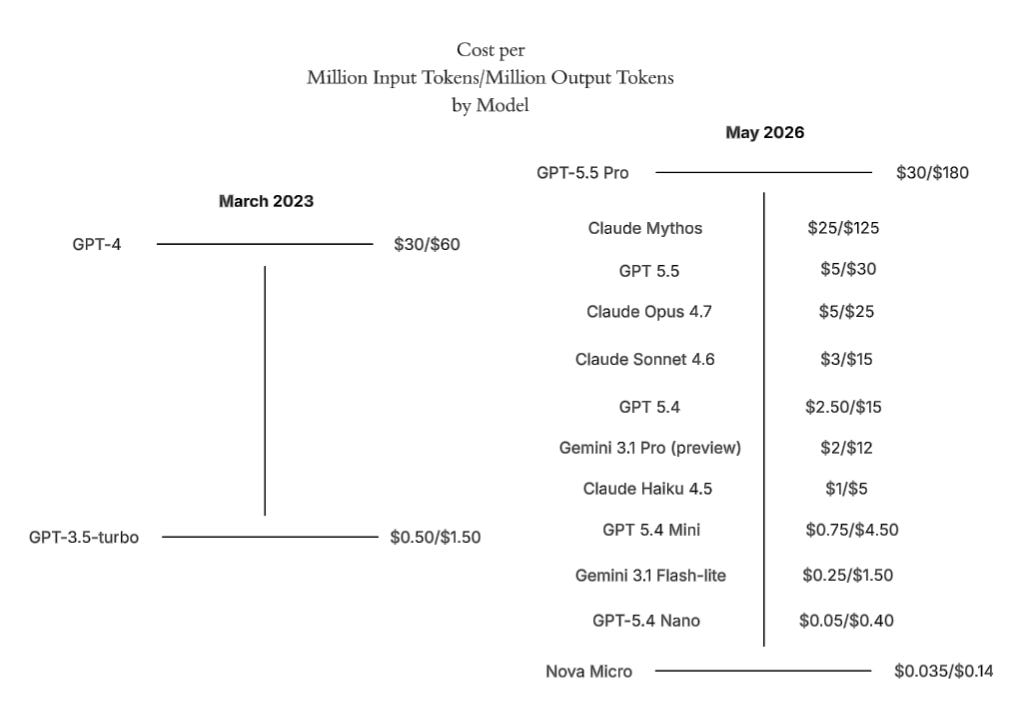
Tokens Are Not Value
But organizations are looking for ROI on valuable work, and not leaderboard points or token maxxing. For the first time, “dumber” models are more than sufficient to get the job done at very high levels of accuracy, especially now that evals, harnesses, and controls are in place.
This is why it’s so hard to project total spend --
As developer and user AI expertise expands, token usage increases, but more can be accomplished with less expensive models.
The old days (a few months ago):
Use most expensive model
“Implement this feature / create this marketing copy / Do the thing!”
“Make up your own tests and make sure to pass them”
“Make no mistakes”
The new days:
Select best model for use case (sometimes far in advance of it actually executing)
[After five iterative rounds of planning and prototyping with the team alongside an AI that is wholly aware of the environment, codebase, and infrastructure] “Execute this detailed plan.”
“You must pass the very extensive tests that already exist. Use these repeatable AI skills that we’ve been refining over months. The tests will block you from submitting and you can’t change them, so you’ll need to pass them.”
Hiding underneath the pricing and cost debate is translation to value. The rate per token matters, but cost per job matters more.
The Macro of Computing Story: Prices are Going Up
Remember “Extended Thinking” from Claude’s models? Turn it on and the model will spend longer verifying its results every time.
Those were the days. Now it’s “Extended thinking.” If it seems like it’s worth the trouble AND Anthropic has enough compute, it will spin longer on it. Model degradations were becoming palpable for users.
Somehow Anthropic’s savior for compute became… Elon Musk? Yes, Anthropic was against the wall, and Elon Musk and xAI came to the rescue with Colossus’s compute that is sufficient (for now) to relieve the pressure.
OpenAI, Anthropic, and Google have locked up the spare compute for training (creating new models) and inference (allowing us to use them).
Intelligence will become increasingly expensive as compute, memory, electricity, or any of the other essential pieces of the supply chain of AI compute is bottlenecked. Without another breakthrough in model efficiency, which we haven’t seen the likes of for over a year, demand is skyrocketing and will outpace supply.
The Fixed Cost of Expertise
That is where the industry is headed on a macro basis, but how do companies react?
The first serious AI buildout rewarded experimentation. Teams were trying to discover what these systems could do, where they broke, and whether any of the demos survived real world contact. During that phase, token spend was often a small percentage of the total cost because the expensive part was human labor.
scope the use case,
design the workflow,
build retrieval,
define evals,
manage stakeholders (so many stakeholders),
review outputs,
iterate with beta users ,
decide whether the whole thing was ready for production or merely marketing
This is the part where “the fixed-cost argument” misses.
Dwarkesh Patel recently discussed AI compute economics with Dylan Patel in an episode focused on the major bottlenecks to scaling AI:
compute
memory
electricity
I’m a big fan of Dwarkesh, but he misses the mark on fixed cost. Here is his argument:
By the way, there’s this interesting economic effect called Alchian-Allen, which is the idea that if you increase the fixed cost of different goods, one of which is higher quality and one which is lower quality, that will make people choose the higher quality good, on the margin.
To give a specific example, suppose the better-tasting apple costs two dollars and the shittier apple costs one dollar. Now suppose you put an import tariff on them. Now it’s $3 versus $2 for a great apple versus a medium apple.
…
So I wonder if applied to AI that would mean that, if GPUs are going to get more expensive, there will be a fixed cost increase in the price of compute. As a result, that will push people to be willing to pay higher margins for slightly better models. Because the calculus is, I’m going to be paying all this money for the compute anyway. I might as well just pay slightly more to make sure it’s the very best model rather than a model that’s slightly worse.
The limitation in Dwarkesh’s argument is that it comes mostly from the lab side and does not consider the fixed costs of those deploying. As expertise increases, the fixed costs associated with launching a product continually decreases. The missing piece is:
Output quality ≠ Model quality
For many companies, the larger fixed cost was the upfront labor required to deploy the system and decide whether the project should exist at all. The model call might have been the cheap part compared with the weeks or months of engineering, evaluation, process design, stakeholder alignment, and the many iterations with users required to make the system useful.
Intelligence is improving, model costs are going up, but teams are getting better at building than ever. (On a related note of increasing AI expertise, you can pick up a copy of our book, Architected Intelligence, today!)
Token Costs as Substitutes for SaaS Subscriptions, Wages, and Contractor Costs
This is also the moment when the Eye of Sauron of finance departments turns toward token spend. Tying each token’s cost to a project will soon become not just normal but mandatory.

At first, finance mostly sees AI as a strategic initiative, an innovation budget, or an executive priority with enough glow and “pizzazz” around it to discourage normal scrutiny. Eventually, AI costs become comparable to, eventually exceeds, some of the major line-item costs of SaaS, vendors, wages, infra, etc. Once that threshold is crossed, a new era arrives.
AI can act as a substitute for SaaS, contractors, vendors, and wages. Once an organization realizes AI costs are BOTH a substitute for other costs and a major budgetary line item, incentives will quickly adapt.
In the new world, a department receives a budget and is then responsible for deploying it however it sees fit. This new realm of responsibility can be both empowering and terrifying. A marketing team will have more autonomy than ever, but accountability will come bundled with it.
With increasing AI expertise, the ROI calculation will become increasingly explicit.
Departments will start asking whether smaller models can do the job. They will ask whether frontier models should be reserved for escalation, review, or high-impact decisions. They will ask whether the entire policy library needs to be injected into context every time someone asks a question that could have been answered by three paragraphs and a citation link. They will ask why an agent used seven tool calls to check whether Tuesday comes after Monday.
This is new, but at least it feels more sustainable than token-maxxing where token volume is the proxy metric for “seriousness around AI adoption.”
So, it’s a race:
AI adoption continues to rapidly increase and permeate more organizations and departments, increasing demand
Compute capacity is increasing, but not fast enough, with demand outpacing supply
AI expertise is increasing, allowing for more selective ROI-based efficiency
While it’s true that “token maxxing endless shrimp” is ending and costs are continuing to increase, with intention and expertise, you can continue to accelerate.