
Why GPT 4.5 Disappointed, and Why That Doesn’t Change Anything

GPT 4.5 was finally released by OpenAI. Rumors of this model began circulating over a year ago. With a knowledge cutoff in October 2023, it is safe to say this model took a long time to develop. Before the livestream, I read through the model card white paper that had been released earlier in the morning. I quickly clued in that this would not be a massive step forward like the name implied. This was further confirmed when I saw the list of speakers for the livestream, which was a collection of random employees. No Sam Altman.
During the livestream, the collection of speakers nervously shared the details of this new model. The gist of the message was that the vibe of this model was better. There were some metrics to back this up, and the following days seem to echo that from users testing the model. But the metrics also didn’t lie: this model offered a very modest performance bump over GPT-4o, and underperformed against the new reasoning models. The final kicker was the pricing: a whopping $75/$150 input/output cost per million tokens. For context, here is a graph I borrowed from a reddit user.
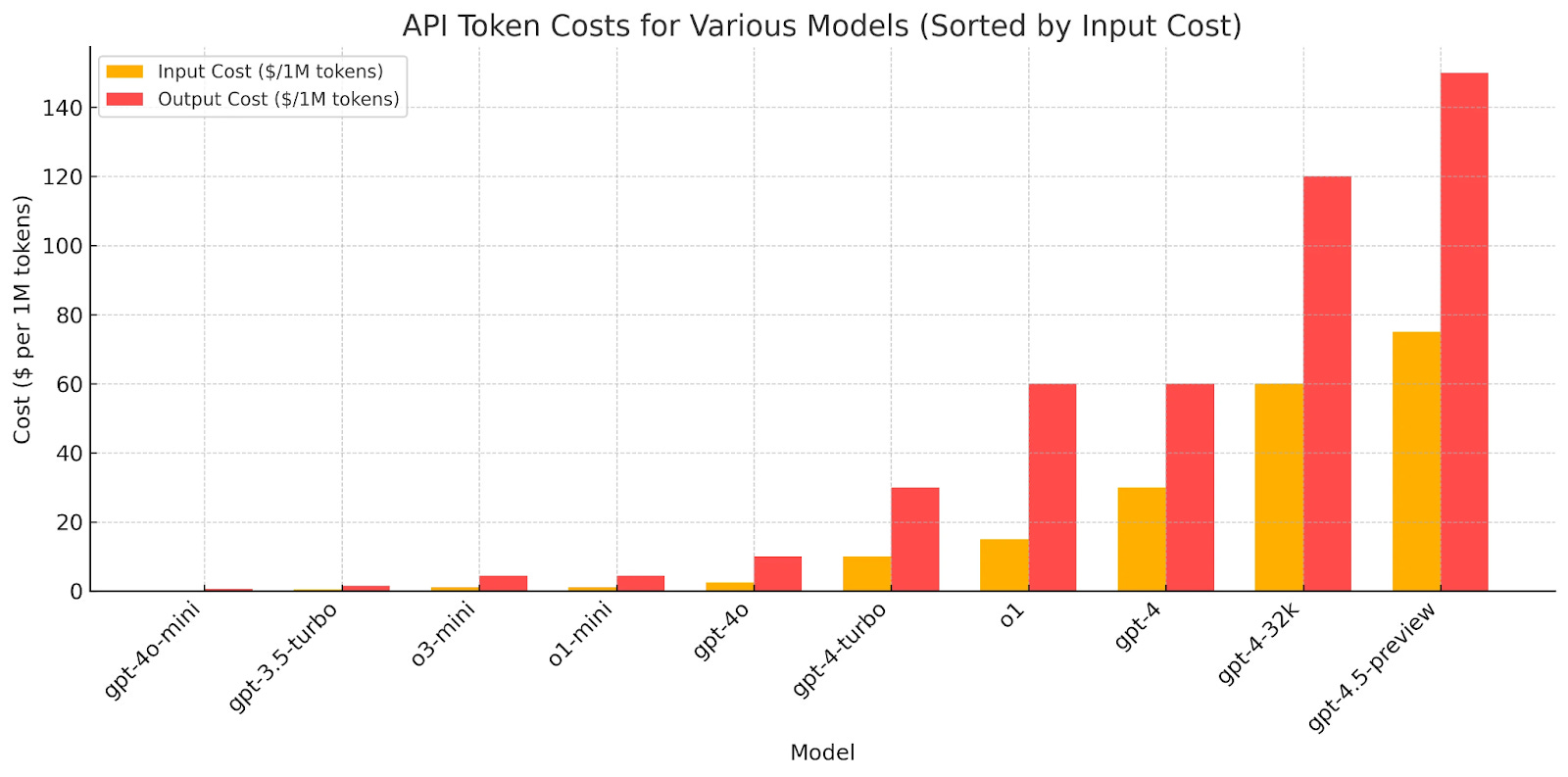
As you can see, GPT-4.5 exceeds even the cost of the original GPT-4 model with an expanded context window.
The reaction on social media was visceral and immediate. I was one of many that expressed my disappointment with the new announcement. In my opinion, calling it GPT-4.5 was bound to lead to missed expectations from users. This may be on purpose to lower the astronomically high expectations people have attached to these model names. That doesn’t change the fact that GPT-4.5 did not meet expectations.
What went wrong here? The general consensus seems to be that the scaling law is becoming too expensive to follow. We’ve tapped out what is currently possible with the chip technology that is available. There is good news on this front. Moore’s law seems to continue to hold true. I feel confident that in the same manner we now have GPT-4o-mini for mere pennies to use, the same reduction in cost will happen with GPT-4.5. The model will become faster and cheaper, a result of both hardware improvement, architectural improvement of the model itself, and distilling the model down to smaller versions. OpenAI claims this model wins in ways that cannot be captured in benchmarks, and I suspect there is some truth to that.
The reality is that the scaling law was already being maxed out a year ago. Many in the community felt this when Sonnet and Haiku (the medium and small models from Anthropic) received impressive new advancements, but the largest model Opus quietly vanished from the headlines. The scaling law is held back by the hardware limitations.
Fortunately, in the same way that Moore’s law continues to work despite generating advancements in different ways, the same is holding true with AI. Sam Altman in his latest blog post tentatively observed a new law with AI:
“The cost to use a given level of AI falls about 10x every 12 months.”
That is an astonishing level of improvement if that continues. And even though the law of scaling has maxed out for now, new avenues of improvement are being discovered. Chief among them is the discovery of reasoning models. Chain of thought was quickly identified as a powerful way to increase the performance of LLMs. By baking this into the models from the start, LLMs are reaching increasingly higher levels of intelligence.
Bottom line: As fast as we can create new benchmarks like Humanity’s Last Exam, AI is already making enormous strides in conquering them. This is why GPT-4.5 disappointed, and why it doesn’t matter. It was a failure because OpenAI has already released reasoning models that far outperform it. GPT-4.5 will be optimized and merged with the advancements from the reasoning models to create even better and more intelligent models, both emotionally and logically.
It's interesting that they said this in their announcement:
"GPT‑4.5 is a very large and compute-intensive model, making it more expensive than and not a replacement for GPT‑4o. Because of this, we’re evaluating whether to continue serving it in the API long-term"